Updated Edition, April 04, 2013: This new edition of our 2012 report on Asian Americans provides data on 14 smaller Asian origin groups with population counts below 500,000 in the 2010 Census, along with detailed data on the economic and demographic characteristics of adults in nine of these groups. Our original 2012 report contained survey and Census data on all Asian Americans as well as specific information on the six largest Asian origin groups.
Asian Americans are the highest-income, best-educated and fastest-growing racial group in the United States. They are more satisfied than the general public with their lives, finances and the direction of the country, and they place more value than other Americans do on marriage, parenthood, hard work and career success, according to a comprehensive new nationwide survey by the Pew Research Center.
A century ago, most Asian Americans were low-skilled, low-wage laborers crowded into ethnic enclaves and targets of official discrimination. Today they are the most likely of any major racial or ethnic group in America to live in mixed neighborhoods and to marry across racial lines. When newly minted medical school graduate Priscilla Chan married Facebook founder Mark Zuckerberg last month, she joined the 37% of all recent Asian-American brides who wed a non-Asian groom.1
These milestones of economic success and social assimilation have come to a group that is still majority immigrant. Nearly three-quarters (74%) of Asian-American adults were born abroad; of these, about half say they speak English very well and half say they don’t.
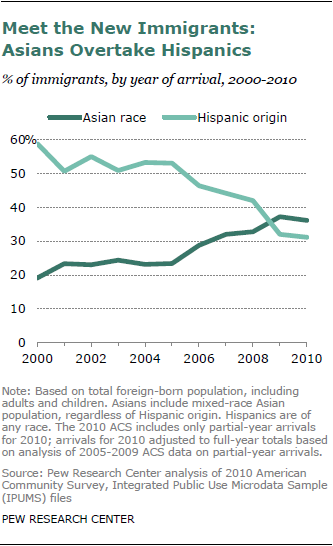
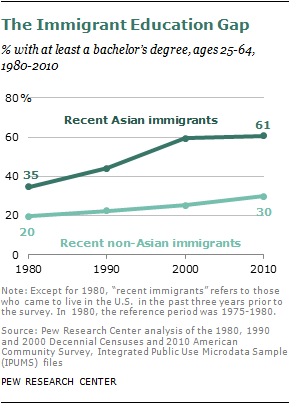
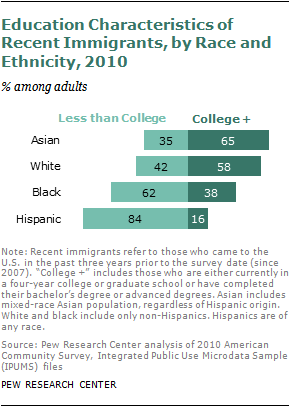
Asians recently passed Hispanics as the largest group of new immigrants to the United States. The educational credentials of these recent arrivals are striking. More than six-in-ten (61%) adults ages 25 to 64 who have come from Asia in recent years have at least a bachelor’s degree. This is double the share among recent non-Asian arrivals, and almost surely makes the recent Asian arrivals the most highly educated cohort of immigrants in U.S. history.
Compared with the educational attainment of the population in their country of origin, recent Asian immigrants also stand out as a select group. For example, about 27% of adults ages 25 to 64 in South Korea and 25% in Japan have a bachelor’s degree or more.2 In contrast, nearly 70% of comparably aged recent immigrants from these two countries have at least a bachelor’s degree.
Recent Asian immigrants are also about three times as likely as recent immigrants from other parts of the world to receive their green cards—or permanent resident status—on the basis of employer rather than family sponsorship (though family reunification remains the most common legal gateway to the U.S. for Asian immigrants, as it is for all immigrants).
The modern immigration wave from Asia is nearly a half century old and has pushed the total population of Asian Americans—foreign born and U.S born, adults and children—to a record 18.2 million in 2011, or 5.8% of the total U.S. population, up from less than 1% in 1965.3 By comparison, non-Hispanic whites are 197.5 million and 63.3%, Hispanics 52.0 million and 16.7% and non-Hispanic blacks 38.3 million and 12.3%.
Asian Americans trace their roots to any of dozens of countries in the Far East, Southeast Asia and the Indian subcontinent. Each country of origin subgroup has its own unique history, culture, language, religious beliefs, economic and demographic traits, social and political values, and pathways into America.
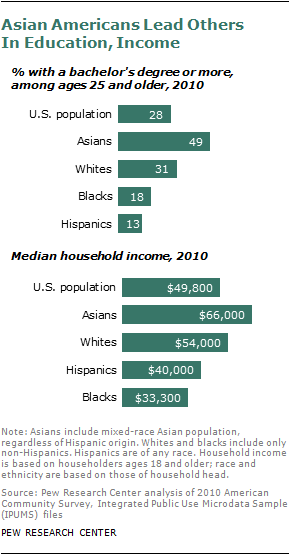
But despite often sizable subgroup differences, Asian Americans are distinctive as a whole, especially when compared with all U.S. adults, whom they exceed not just in the share with a college degree (49% vs. 28%), but also in median annual household income ($66,000 versus $49,800) and median household wealth ($83,500 vs. $68,529).4
They are noteworthy in other ways, too. According to the Pew Research Center survey of a nationally representative sample of 3,511 Asian Americans, conducted by telephone from Jan. 3 to March 27, 2012, in English and seven Asian languages, they are more satisfied than the general public with their lives overall (82% vs. 75%), their personal finances (51% vs. 35%) and the general direction of the country (43% vs. 21%).
They also stand out for their strong emphasis on family. More than half (54%) say that having a successful marriage is one of the most important things in life; just 34% of all American adults agree. Two-thirds of Asian-American adults (67%) say that being a good parent is one of the most important things in life; just 50% of all adults agree.
Their living arrangements align with these values. They are more likely than all American adults to be married (59% vs. 51%); their newborns are less likely than all U.S. newborns to have an unmarried mother (16% vs. 41%); and their children are more likely than all U.S. children to be raised in a household with two married parents (80% vs. 63%).
They are more likely than the general public to live in multi-generational family households. Some 28% live with at least two adult generations under the same roof, twice the share of whites and slightly more than the share of blacks and Hispanics who live in such households. U.S. Asians also have a strong sense of filial respect; about two-thirds say parents should have a lot or some influence in choosing one’s profession (66%) and spouse (61%).
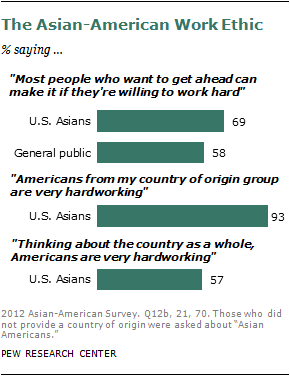
Asian Americans have a pervasive belief in the rewards of hard work. Nearly seven-in-ten (69%) say people can get ahead if they are willing to work hard, a view shared by a somewhat smaller share of the American public as a whole (58%). And fully 93% of Asian Americans describe members of their country of origin group as “very hardworking”; just 57% say the same about Americans as a whole.
By their own lights, Asian Americans sometimes go overboard in stressing hard work. Nearly four-in-ten (39%) say that Asian-American parents from their country of origin subgroup put too much pressure on their children to do well in school. Just 9% say the same about all American parents. On the flip-side of the same coin, about six-in-ten Asian Americans say American parents put too little pressure on their children to succeed in school, while just 9% say the same about Asian-American parents. (The publication last year of “Battle Hymn of the Tiger Mother,” a comic memoir about strict parenting by Yale Law Professor Amy Chua, the daughter of immigrants, triggered a spirited debate about cultural differences in parenting norms.)
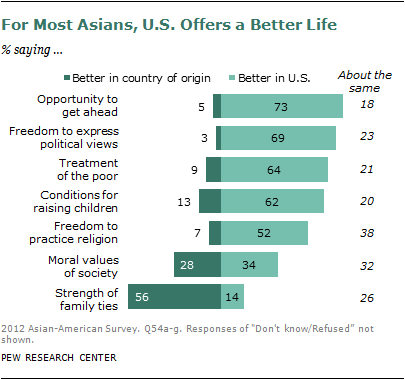
The immigration wave from Asia has occurred at a time when the largest sending countries have experienced dramatic gains in their standards of living. But few Asian immigrants are looking over their shoulders with regret. Just 12% say that if they had to do it all over again, they would remain in their country of origin. And by lopsided margins, Asian Americans say the U.S. is preferable to their country of origin in such realms as providing economic opportunity, political and religious freedoms, and good conditions for raising children. Respondents rated their country of origin as being superior on just one of seven measures tested in the survey—strength of family ties.
(The survey was conducted only among Asian Americans currently living in the U.S. As is the case with all immigration waves, a portion of those who came to the U.S. from Asia in recent decades have chosen to return to their country of origin. However, return migration rates are estimated to be lower for immigrants from Asia than for other immigrants, and naturalization rates—that is, the share of eligible immigrants who become U.S. citizens—are higher. For more details, see Chapter 1.)
Asians in the U.S. and in Asia
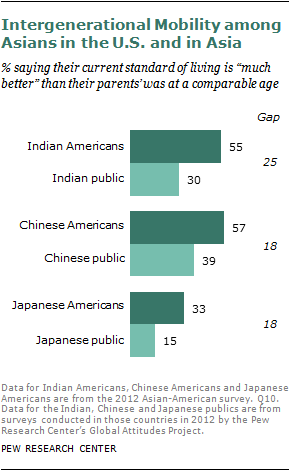
When findings from this survey are compared with recent surveys conducted by the Pew Research Center’s Global Attitudes Project among Asians in major Asian countries, a mixed picture emerges. For example, adults living in China are more satisfied with the way things are going in their country than Chinese Americans are with the way things are going in the United States. By contrast, the publics of India and Japan have a more downbeat view of the way things are going in their countries than their counterpart groups do about the U.S.
Across the board, however, U.S. Asians are more likely than Asians in Asia to say their standard of living is better than that of their parents at a similar stage of life. U.S. Asians also exceed Asians in their belief that hard work leads to success in life. And while many U.S. Asians say that Asian-American parents place too much pressure on their children to do well in school, even more Chinese and Japanese say this about parents in their countries. (For more details on these and other cross-national comparisons, see Chapter 4.)
Differences among Asian-American Subgroups
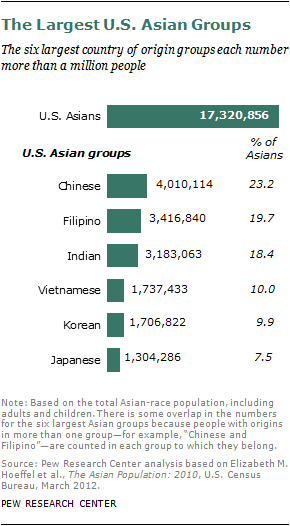
The Pew Research Center survey was designed to contain a nationally representative sample of each of the six largest Asian-American groups by country of origin—Chinese Americans, Filipino Americans, Indian Americans, Vietnamese Americans, Korean Americans and Japanese Americans. Together these groups comprise at least 83% of the total Asian population in the U.S.5
The basic demographics of these groups are different on many measures. For example, Indian Americans lead all other groups by a significant margin in their levels of income and education. Seven-in-ten Indian-American adults ages 25 and older have a college degree, compared with about half of Americans of Korean, Chinese, Filipino and Japanese ancestry, and about a quarter of Vietnamese Americans.
On the other side of the socio-economic ledger, Americans with Korean, Vietnamese, Chinese and “other U.S. Asian”6 origins have higher shares in poverty than does the U.S. general public, while those with Indian, Japanese and Filipino origins have lower shares.7
Their geographic settlement patterns also differ. More than seven-in-ten Japanese and two-thirds of Filipinos live in the West, compared with fewer than half of Chinese, Vietnamese and Koreans, and only about a quarter of Indians.
The religious identities of Asian Americans are quite varied. According to the Pew Research survey, about half of Chinese are unaffiliated, most Filipinos are Catholic, about half of Indians are Hindu, most Koreans are Protestant and a plurality of Vietnamese are Buddhist. Among Japanese Americans, no one group is dominant: 38% are Christian, 32% are unaffiliated and 25% are Buddhist. In total, 26% of Asian Americans are unaffiliated, 22% are Protestant (13% evangelical; 9% mainline), 19% are Catholic, 14% are Buddhist, 10% are Hindu, 4% are Muslim and 1% are Sikh. Overall, 39% of Asian Americans say religion is very important in their lives, compared with 58% of the U.S. general public.
There are subgroup differences in social and cultural realms as well. Japanese and Filipino Americans are the most accepting of interracial and intergroup marriage; Koreans, Vietnamese and Indians are less comfortable. Koreans are the most likely to say discrimination against their group is a major problem, and they are the least likely to say that their group gets along very well with other racial and ethnic groups in the U.S. In contrast, Filipinos have the most upbeat view of intergroup relations in the U.S.
The Japanese are the only group that is majority U.S. born (73% of the total population and 68% of adults); all other subgroups are majority foreign born.
Their pathways into the U.S. are different. About half of all Korean and Indian immigrants who received green cards in 2011 got them on the basis of employer sponsorship, compared with about a third of Japanese, a fifth of Chinese, one-in-eight Filipinos and just 1% of Vietnamese. The Vietnamese are the only major subgroup to have come to the U.S. in large numbers as political refugees; the others say they have come mostly for economic, educational and family reasons.
Asian Americans have varying degrees of attachment to relatives in their home countries—likely reflecting differences in the timing and circumstances of their immigration. For example, though they are among the least well-off financially, Vietnamese Americans are among the most likely (58%) to say they have sent money to someone in Vietnam in the past year. About half of Filipinos (52%) also say they sent remittances home in the past year. By contrast, Japanese (12%) and Koreans (16%) are much less likely to have done this.
They have different naturalization rates. Fully three-quarters of the foreign-born Vietnamese are naturalized U.S. citizens, compared with two-thirds of Filipinos, about six-in-ten Chinese and Koreans, half of Indians and only a third of Japanese.
History
Asian immigrants first came to the U.S. in significant numbers more than a century and a half ago—mainly as low-skilled male laborers who mined, farmed and built the railroads. They endured generations of officially sanctioned racial prejudice—including regulations that prohibited the immigration of Asian women; the Chinese Exclusion Act of 1882, which barred all new immigration from China; the Immigration Act of 1917 and the National Origins Act of 1924, which extended the immigration ban to include virtually all of Asia; and the forced relocation and internment of about 120,000 Japanese Americans after the Japanese attack on Pearl Harbor in 1941.
Large-scale immigration from Asia did not take off until the passage of the landmark Immigration and Nationality Act of 1965. Over the decades, this modern wave of immigrants from Asia has increasingly become more skilled and educated. Today, recent arrivals from Asia are nearly twice as likely as those who came three decades ago to have a college degree, and many go into high-paying fields such as science, engineering, medicine and finance. This evolution has been spurred by changes in U.S. immigration policies and labor markets; by political liberalization and economic growth in the sending countries; and by the forces of globalization in an ever-more digitally interconnected world.
These trends have raised the education levels of immigrants of all races in recent years, but Asian immigrants exceed other race and ethnic groups in the share who are either college students or college graduates.
Native Born and Foreign Born
Throughout the long history of immigration waves to the U.S., the typical pattern has been that over time the second generation (i.e., the children of immigrants) surpasses the immigrant generation in key measures of socio-economic well-being and assimilation, such as household income, educational attainment and English fluency.
It is not yet possible to make any full intergenerational accounting of the modern Asian-American immigration wave; the immigrants themselves are still by far the dominant group and the second generation has only recently begun to come into adulthood in significant numbers. (Among all second-generation Asians, the median age is just 17; in other words, about half are still children.)

But on the basis of the evidence so far, this immigrant generation has set a bar of success that will be a challenge for the next generation to surpass. As of now, there is no difference in the share of native- and foreign-born Asian Americans ages 25 and older who have a college degree (49% for each group), and there is only a modest difference in the median annual earnings of full-time workers in each group ($50,000 for the native born; $47,000 for the foreign born). The two groups also have similar shares in poverty and homeownership rates.
Not surprisingly, when it comes to language fluency, there are significant differences between the native- and foreign-born adults. Only about half (53%) of the foreign born say they speak English very well, compared with 95% of the U.S. born. Family formation patterns are also quite different. The U.S. born are much less likely than the foreign born to be married (35% vs. 67%), a difference largely driven by the fact that they are a much younger group. (Among adults, the median age is 30, versus 44 for the foreign born.)
There are also differences between the native born and foreign born in the share of recent mothers who are unmarried. About three-in-ten (31%) U.S.-born Asian women who had children recently are unmarried, compared with just 10% of all recent foreign-born Asian-American mothers. Among the U.S. population as a whole, about four-in-ten recent American mothers are unmarried. Even as births to single mothers have become more widespread in recent decades, Pew Research surveys find that a sizable majority of Americans believe this growing phenomenon has been bad for society. So in the eyes of the public, this appears to be a case of “downward assimilation” by second generation and later generations of Asian Americans to an increasingly prevalent—but still frowned upon—U.S. pattern of behavior.8
On a more positive note, U.S.-born Asians are more upbeat than the foreign born about their relations with other racial and ethnic groups, and they are more receptive to the growing practice of racial and ethnic intermarriage.
Perceptions of Discrimination
For the most part, today’s Asian Americans do not feel the sting of racial discrimination or the burden of culturally imposed “otherness” that was so much a part of the experience of their predecessors who came in the 19th and early 20th centuries.
About one-in-five Asian Americans say they have personally been treated unfairly in the past year because they are Asian, and one-in-ten say they have been called an offensive name. Older adults are less likely than young and middle-aged adults to report negative personal experience with bias.
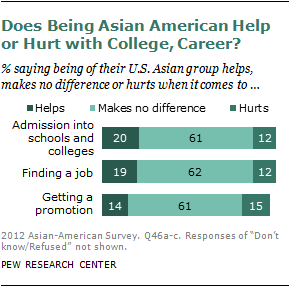
Compared with the nation’s two largest minority groups—Hispanics and blacks—Asian Americans appear to be less inclined to view discrimination against their group as a major problem. Just 13% of Asian Americans say it is, while about half (48%) say it is a minor problem, and a third (35%) say it is not a problem.9
About six-in-ten say that being Asian American makes no difference when it comes to getting a job or gaining admission to college. Of those who do say it makes a difference, a slightly higher share say that members of their group are helped rather than hurt by their race. Those with less education are more prone than those with more education to say that being an Asian American is an advantage.
Group Relations
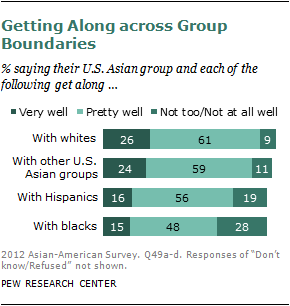
Overall, more than eight-in-ten Asian Americans say their group gets along either very or pretty well with whites; roughly seven-in-ten say the same about relations with Hispanics and just over six-in-ten say that about their relations with blacks. Korean Americans stand out for their negative views on their group’s relations with blacks. Fully half say these two groups don’t get along well; while 39% say they get along pretty well and just 4% say they get along very well. In several cities across the country, there has been a history of tension between Koreans and blacks, often arising from friction between Korean shopkeepers and black customers in predominantly black neighborhoods.
About four-in-ten Asian Americans say their circle of friends is dominated by Asians from the same country of origin, while 58% say it is not. Among U.S.-born Asians, however, just 17% say that all of most of their friends are from their same country of origin group.
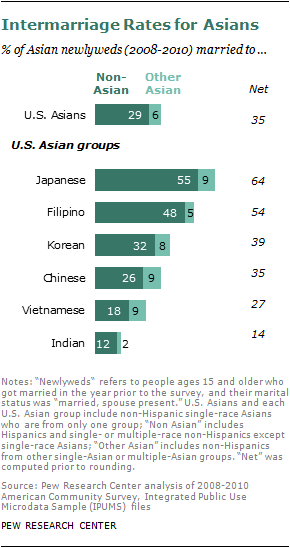
Asian-American newlyweds are more likely than any other major racial or ethnic group to be intermarried. From 2008 to 2010, 29% of all Asian newlyweds married someone of a different race, compared with 26% of Hispanics, 17% of blacks and 9% of whites. There are notable gender differences. Asian women are twice as likely as Asian men to marry out. Among blacks, the gender pattern runs the other way—men are more than twice as likely as women to marry out. Among whites and Hispanics, there are no differences by gender.
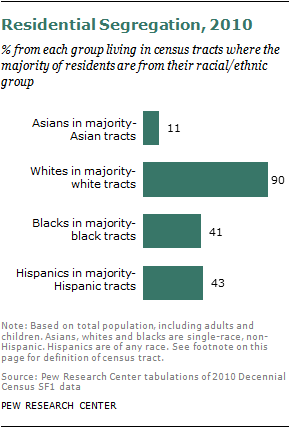
Among Asian-American newlyweds, Japanese have the highest rate of intermarriage and Indians have the lowest. More than half of recent Japanese newlyweds married a non-Asian; among recent Indian newlyweds, just one-in-eight did.
Asian Americans were once highly concentrated into residential enclaves, exemplified by the establishment of “Chinatowns” and other Asian communities in cities across the country. Today, however, Asian Americans are much more likely than any other racial group to live in a racially mixed neighborhood. Just 11% currently live in a census tract in which Asian Americans are a majority.10 The comparable figures are 41% for blacks, 43% for Hispanics and 90% for whites. (This comparison should be treated with caution: Each of the other groups is more numerous than Asians, thereby creating larger potential pools for racial enclaves.)
Identity
Despite high levels of residential integration and out-marriage, many Asian Americans continue to feel a degree of cultural separation from other Americans. Not surprisingly, these feelings are highly correlated with nativity and duration of time in the U.S.
Among U.S.-born Asian Americans, about two-thirds (65%) say they feel like “a typical American.” Among immigrants, just 30% say the same, and this figure falls to 22% among immigrants who have arrived since 2000.
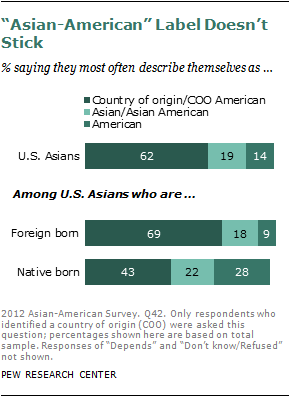
The Asian-American label itself doesn’t hold much sway with Asian Americans. Only about one-in-five (19%) say they most often describe themselves as Asian American or Asian. A majority (62%) say they most often describe themselves by their country of origin (e.g., Chinese or Chinese American; Vietnamese or Vietnamese American, and so on), while just 14% say they most often simply call themselves American. Among U.S.-born Asians, the share who most often call themselves American rises to 28%.
In these identity preferences, Asian Americans are similar to Hispanics, the other group that has been driving the modern immigration wave. Hispanics are more likely to identify themselves using their country of origin than to identify as a Hispanic or as an American.11
Perceptions of Success
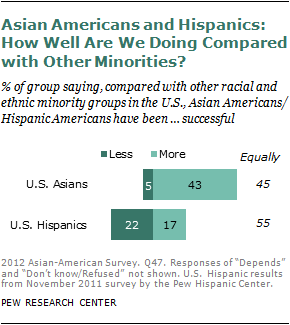
About four-in-ten Asian Americans (43%) say Asian Americans are more successful than other racial and ethnic minorities in the U.S. A similar share of Asian Americans (45%) say they are about as successful, and just 5% say they are less successful.
Native-born and foreign-born Asian Americans have similar views about their groups’ success relative to other minorities. Recent immigrants, however, tend to be somewhat less upbeat in these assessments than are immigrants who came before 2000: 36% of the former versus 48% of the latter say their group has been more successful than other minority groups in the U.S.
Members of the nation’s other large immigrant group—Hispanics—are less than half as likely as Asian Americans to say their group is more successful than other racial and ethnic minorities, and they are four times as likely to say they are less successful.12
On a personal level, Asian Americans are more satisfied than the general public with their financial situations and their standard of living. When measured against how well their parents were doing at the same stage of life, about half (49%) say they are doing much better, and a quarter say they are doing somewhat better. By contrast, only about a third of all Americans say they are doing much better than their parents at a similar stage of life.
There are only minor differences between Asian Americans and the general public in their expectations about the upward mobility of their children. Some 31% of Asian Americans believe that when their children are the age they are now, their children will have a much better standard of living, 22% say somewhat better, 19% say about the same, and 19% say somewhat or much worse.
On this measure, there are sizable differences among U.S. Asian subgroups. Nearly half of Vietnamese Americans (48%) say they expect their children eventually to have a much better standard of living than they themselves have now. About a third of Koreans and Indians feel this way, as do one-in-four Chinese and Filipinos, and just one-in-five Japanese. Overall, the foreign born are more optimistic than the native born about their children’s future standard of living relative to their own at the present.
Political and Social Attitudes
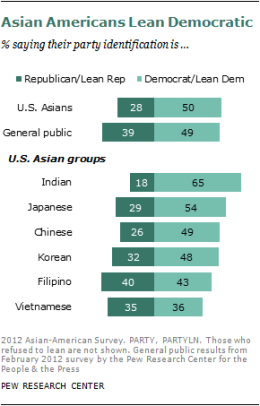
Compared with the general public, Asian Americans are more likely to support an activist government and less likely to identify as Republicans. Half are Democrats or lean Democratic, while only 28% identify with or lean toward the GOP. Among all American adults, 49% fall in the Democratic camp and 39% identify with or lean toward the Republican Party. Indian Americans are the most heavily Democratic Asian subgroup (65%), while Filipino Americans and Vietnamese Americans are the most evenly split between the two parties.
President Obama gets higher ratings from Asian Americans than from the general public —54% approve of the way he is handling his job as president, compared with 44% of the general public. In 2008, Asian-American voters supported Obama over Republican John McCain by 62% to 35%, according to Election Day exit polls.13
On balance, Asian Americans prefer a big government that provides more services (55%) over a smaller government than provides fewer services (36%). In contrast, the general public prefers a smaller government over a bigger government, by 52% to 39%.
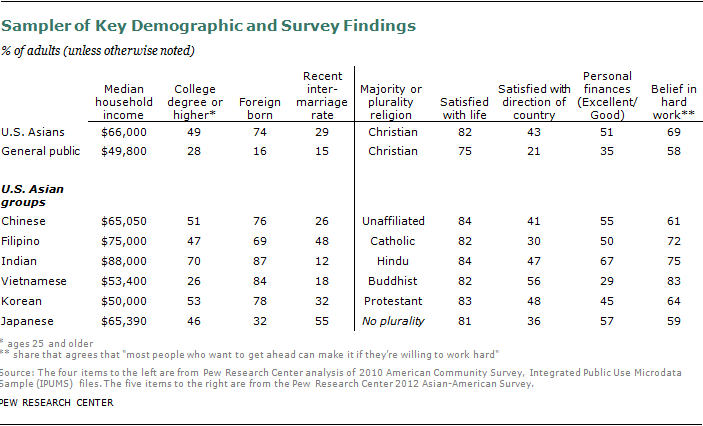
While they differ on the role of government, Asian Americans are close to the public in their opinions about two key social issues. By a ratio of 53% to 35%, Asian Americans say homosexuality should be accepted by society rather than discouraged. And on the issue of abortion, 54% of Asian Americans say it should be legal in all or most cases, while 37% say it should be illegal.
About the Survey
The Pew Research Center’s 2012 Asian-American Survey is based on telephone interviews conducted by landline and cell phone with a nationally representative sample of 3,511 Asian adults ages 18 and older living in the United States. The survey was conducted in all 50 states, including Alaska and Hawaii, and the District of Columbia. The survey was designed to include representative subsamples of the six largest Asian groups in the U.S. population: Chinese, Filipino, Indian, Japanese, Korean and Vietnamese. The survey also included Asians from other Asian subgroups.
Respondents who identified as “Asian or Asian American, such as Chinese, Filipino, Indian, Japanese, Korean, or Vietnamese” were eligible to complete the survey interview, including those who identified with more than one race and regardless of Hispanic ethnicity. The question on racial identity also offered the following categories: white, black or African American, American Indian or Alaska Native, and Native Hawaiian or other Pacific Islander.
Classification into U.S. Asian groups is based on self-identification of respondent’s “specific Asian group.” Asian groups named in this open-ended question were “Chinese, Filipino, Indian, Japanese, Korean, Vietnamese, or of some other Asian background.” Respondents self-identified with more than 22 specific Asian groups. Those who identified with more than one Asian group were classified based on the group with which “they identify most.” Respondents who identified their specific Asian group as Taiwanese or Chinese Taipei are classified as Chinese Americans for this report.
The survey was conducted using a probability sample from multiple sources. The data are weighted to produce a final sample that is representative of Asian adults in the United States. Survey interviews were conducted under the direction of Abt SRBI, in English and Cantonese, Hindi, Japanese, Korean, Mandarin, Tagalog and Vietnamese. For more details on the methodology, see Appendix 1.
- The survey was conducted Jan. 3-March 27, 2012 in all 50 states, including Alaska and Hawaii, and the District of Columbia.
- 3,511 interviews including 728 interviews with Chinese Americans, 504 interviews with Filipino Americans, 580 interviews with Indian Americans, 515 interviews with Japanese Americans, 504 interviews with Korean Americans, 504 interviews with Vietnamese Americans and 176 interviews with Asians of other backgrounds.
- Margin of error is plus or minus 2.4 percentage points for results based on the total sample at the 95% confidence level. Margins of error for results based on subgroups of Asian Americans, ranging from 3.1 to 7.8 percentage points, are included in Appendix 1.
Notes on Terminology
Unless otherwise noted, survey results for “Asian Americans” and “U.S. Asians” refer to adults living in the United States, whether U.S. citizens or not U.S. citizens and regardless of immigration status. Both terms are used interchangeably. Adults refers to those ages 18 and older.
U.S. Asian groups, subgroups, heritage groups and country of origin groups are used interchangeably to reference respondent’s self-classification into “specific Asian groups.” This self-identification may or may not match a respondent’s country of birth or their parent’s country of birth.
Unless otherwise noted, whites include only non-Hispanic whites. Blacks include only non-Hispanic blacks. Hispanics are of any race. Asians can also be Hispanic.
Poverty is calculated based on the total population. For this and other reasons, the share in poverty in this report is not comparable with the Census Bureau’s official poverty rate. (Note: The report was revised July 12, 2012 to change “poverty rate” to “% in poverty” or “share in poverty,” and to add a definition to Notes on Terminology.)





